
1- O Equipamento
Para se escanear é preciso um scaner. O meu possui Resolução Óptica: 1200 x 600 dpi (dpi = pontos por polegada). Para reconhecimento de texto isso é mais do que o necessário (veja o item mais abaixo sobre configurações do programa). Hoje (domingo, 8 de agosto de 2004) um scaner de boa qualidade custa entre R$ 300 e R$ 400, de marcas como HP, Epson, Genius, Canon. Existem equipamentos mais baratos, na faixa dos R$ 200 (marcas como Bright, TCE, etc) que podem até funcionar, mas eu não recomendaria a ninguém (ou, quem sabe, para alguém de quem não goste?) Obs.: Muitos equipamentos vem indicando nas suas caixas e/ou propagandas resoluções de 9200 dpi, 14400 dpi ou mais. Na realidade estas resoluções são interpoladas, ou seja, o scaner escaneia a imagem com a máxima resolução óptica possível (em geral 600, 1200 ou 2400 nos scaners mais modernos [e mais caros] e os pontos faltantes são “chutados” pelo equipamento, com base nos pontos efetivamente escaneados)
2- Os programas
Para transformar a imagem que o scaner capta em texto editável utiliza-se de um programa OCR (OCR = optical character recognition = Reconhecimento Óptico de Caracteres). Todos scaners já vem com um programa destes, porém em versões simplificadas. É altamente recomendável pegar as versões completas. Existem vários deles, tais como(em suas versões mais atuais): Cuneiform Pro 6.0, Readiris Pro 9, FineReader 7.0 pro, OmniPage 14, etc. Todos podem ser baixados pela internet. Desses eu ainda não testei o ReadIris. Os programas Omnipage e FineReader tem desempenho similar, com o Omnipage um pouquinho (mas muito pouquinho mesmo) superior na área do reconhecimento. Eu prefiro usar o FineReader pois:
- No omnipage primeiro você escaneia uma página, ou conjunto de duas páginas de um livro, depois o programa faz o reconhecimento da página e então permite a você escanear outra página. Já O FineReader aproveita o tempo em que o scaner está funcionando para o reconhecimento. Com isso todo o processo é feito na metade do tempo (no meu equipamento, utilizando a resolução de 300 dpi, leva cerca de 1 minuto por conjunto de duas página de um livro)
- O tamanho do arquivo do Omnipage é mais de 600 Mb, enquanto que o do FineReader 42 Mb, o que é muito mais fácil de baixar pela internet (é claro que você pode recorrer a um “distribuidor não oficia” e por “deis real” adquirir o CD do Omnipage) e ocupa, quando instalado, menor espaço na HD do seu micro e menos recursos do equipamento. Ambos os programas possuem a capacidade de automaticamente reconhecer textos e figuras. Quando existe uma figura na página escaneada ela é mantida mais ou menos na mesma posição do
original.
A partir de agora este texto versará sobre o programa FineReader.
3- Onde Conseguir o Fine Reader
OFF
4- Configurações do programa:
Use resolução de 300 dpi para textos normais (tamanho de fonte de 10 pts. ou maior) e resolução de 400-600 dpi para textos definidos em tamanhos pequenos de fonte (9 pts. ou menor). O escaneamento no modo de escala cinza é o melhor para os propósitos de reconhecimento. Se escanear suas imagens na escala cinza, o brilho será ajustado automaticamente. Se desejar visualizar a caixa de diálogo Configurações do Scanner no modo Usar Interface do FineReader, selecione a caixa de diálogo Opções de Exibição antes do item de escaneamento na guia Escanear/Abrir Imagem (Ferramentas>Opções).
Minha experiência: No meu scaner o tempo de escaneamento no modo escala de cinza e no modo preto e branco é exatamente o mesmo, para a resolução de 300 dpi. E o resultado é um pouco melhor no modo tons de cinza. Recentemente testei com menor resolução (200 dpi).O tempo de escaneamento foi apenas um pouco menor (uns cinco segundos) O reconhecimento também foi um pouco pior. Minha recomendação: Modo escala de cinza e 300 dpi como padrão. Se o original for muito ruim, aumentar a resolução.
5-O escaneamento
O FineReader por padrão usa o português de Portugal. Como o programa automaticamente faz algumas correções no texto, se no original estiver, por exemplo, a palavra quilômetro o programa vai transformá-la em quilómetro
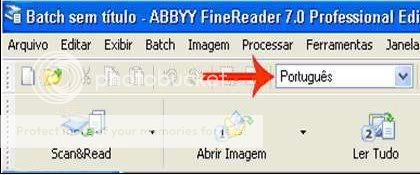
É preciso baixar pela internet o arquivo de idioma Português(Brasil).
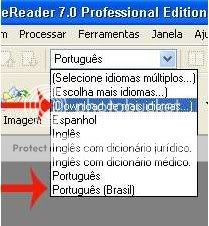
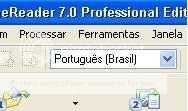
Toda vez que for escanear é preciso selecionar Português (Brasil) (A não ser que o livro esteja escrito em português de Portugal, ora pois)
Com o scaner ligado, o livro posicionado, vamos indicar ao programa que iremos escanear múltiplas páginas. Para isso clicamos sobre o pequeno triângulo preto no botão Scan & read.
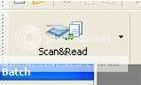
E escolhemos a opção Scan&Read para Imagens Múltiplas.
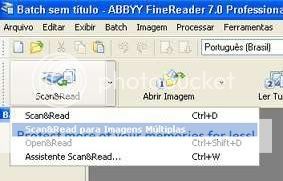
Automaticamente o programa vai abrir a interface do scaner. Está interface varia de scaner para scaner, mantendo certa similaridade. Você poderá então ajustar as configurações (no exemplo o scaner está configurado para 300 dpi, tons de cinza) e área a ser escaneada(o retângulo tracejado).
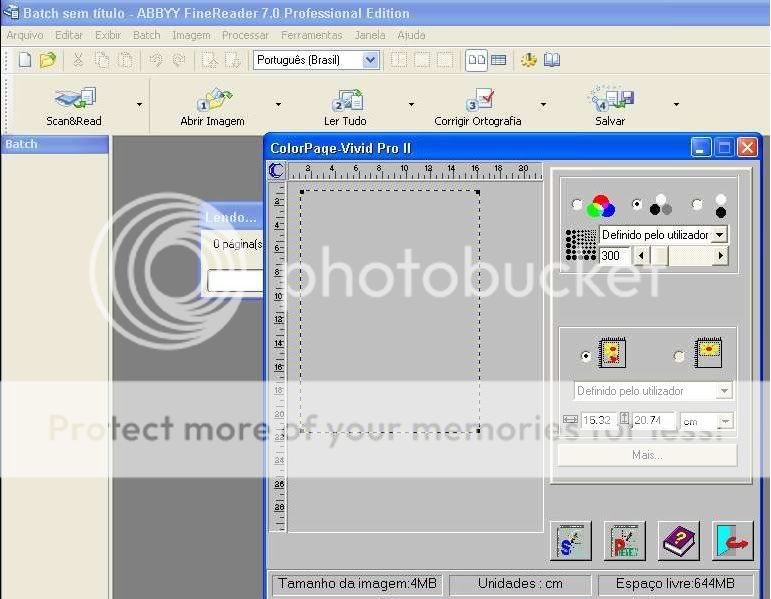
Para determinar a área a ser escaneada basta colocar o original no scaner e ler o valor das réguas do scaner. A escolha da área influencia diretamente o tempo de escaneamento, quanto menor a área, menor o tempo. Como existem margens nos livros eu procuro descontar essas margens na área escaneada, mas isso, dependendo das margens, permite uma redução de no máximo 5 segundos. no tempo de escaneamento. Há uma outra função para esta escolha de área. Todo livro vem com as páginas numeradas, e essa numeração fica a uma certa distância do texto das páginas. Graças a essa distância é possível escolher a área de forma a não ser escaneada a numeração da página. Você é quem deve decidir se isso é importante ou não. Se escanear a numeração fica mais fácil, caso haja algum problema no texto escaneado (e, para um livro, sempre tem), localizar no original e
corrigir. Como a formatação do texto escaneado nunca é a mesma do original a numeração escaneada em geral aparece nos lugares errados, no meio da página e às vezes até duas vezes em uma mesma página. Eu prefiro eliminar a numeração e, durante a pré-revisão, ir acompanhando com o livro. Mas você pode escanear a numeração das páginas e eliminá-la durante a pré-revisão, o que dá um pouco mais de trabalho. (o que é pré-revisão eu explico mais adiante).
Ah, sim, eu ia me esquecendo da posição do livro. Podemos identificar 2 posições básicas do livro no scaner, que identificaremos como “de pé” e “de lado”. Qual que é qual não é muito importante pois o programa vem configurado para automaticamente determinar isso. Resumindo: Bota o livro no scaner e deixa o programa se virar! É claro que se deve colocar o livro de tal forma que toda a área do mesmo seja exposta á luz do scaner.
Estando tudo pronto basta clicar no botão que inicia o escaneamento (na figura o botão com o S azul). As páginas diretamente sobre o scaner serão escaneadas. Então é só virar a página, colocar o livro na mesma posição e apertar o botão de escaneamento de novo, e assim sucessivamente. Quando tudo já tiver escaneado é só fechar a interface do scaner (aperta o X do canto superior direito ou o botão de sair, que no meu scaner é indicado pelo quarto botão na figura anterior, aquele com o
desenho de uma porta azul aberta e uma seta vermelha). Neste momento o que estiver escaneado já foi tudo reconhecido e basta agora salvar no formato desejado.
Importante: Enquanto estiver escaneando não é possível salvar. Considerando que meu scaner leva 1 minuto por par de páginas, um livro de duzentas páginas levará 100 minutos (é uma hora e quarenta minutos) para ser escaneados. É recomendável não escanear o livro de uma vez só e sim em doses homeopáticas para evitar a frustração de, quando (de acordo com as leis de Murphy é quando e não se) quase no fim do serviço faltar energia elétrica ou o computador travar e você perder todo o serviço. Aí você vai ficar com raiva, chutar o computador e quebrar a ambos (o computador e o pé). Portanto, por questões de saúde e economia, escaneie um pouco por dia!
6-A Salvação
Caríssimos irmãos! É chegado um dos momentos mais importantes. Vamos salvar o nosso arquivo! Não deixemos que seja ele defenestrado do nosso Windows. Vamos então diretamente ao último dos grandes cinco botões de FineReader. O botão Salvar!
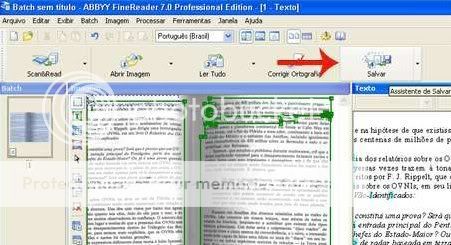
Ao clicarmos no botão surge imediatamente a janela Assistente de salvar.
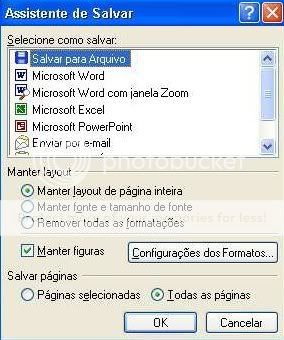
Importante. Certifique-se de que o item “Todas as páginas” esteja selecionado, caso contrário só a última página, que é automaticamente selecionada, será salva. Você pode também selecionar várias paginas para que apenas estas, caso o item “Páginas selecionadas” esteja selecionados, sejam salvas. Mas na maioria das vezes serão salvas todas as páginas. O padrão do FineReader é “Página selecionadas” mas basta alterar esta seleção que para as próximas vezes já venha o item “Todas as
páginas” selecionado.
Repare que na parte superior, em “Selecione como salvar”, há uma lista de itens. O primeiro é “Salvar para Arquivo”, que, quando selecionado e clicado no botão OK, abre a janela “Salvar texto como”, que permite escolher entre diversos formatos, tais como doc, rtf, pdf, hml, ppt.
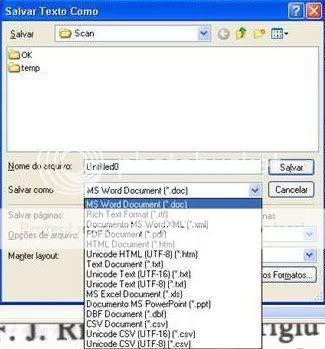
Voltando ao “Selecione como salvar”, o item seguinte é Microsoft Word. Com esse item selecionado, ao clicar no botão OK será aberto o programa Word(mas só se ele estiver instalado no seu micro!) e o texto escaneado é transferido para ele. Note que isso é feito sem haver salvamento do texto, que deverá ser feito diretamente no Word. Os outros itens dessa lista (Excel, PowerPoint, etc) devem funcionar de maneira análoga (eu nunca testei)
Tanto na janela Assistente de Salvar quanto na Salvar Texto Como existe o botão Configurações dos formatos, que abre a janela Configurações dos Formatos.
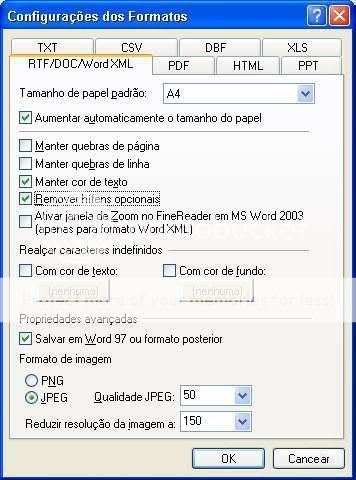
Esta janela permite algumas alterações nos formatos do texto e das imagens a serem salvas. Em geral não há a necessidade de alterar nada aqui. Uma parte importante do processo de salvamento está relacionada com a área central da janela Assistente de Salvar onde aparecem os itens listados sob o nome Manter Layout.
As três opções determinam como o arquivo será salvo em relação ao formato do original:
> Manter Layout da página inteira: isto faz a formatação do texto escaneado ficar o mais parecido possível com a formatação do original. Se você escanear o livro aberto, o resultado vai ser uma página de duas colunas, cada coluna representando uma das páginas do livro. A numeração do livro, se escaneada, vai estar numerando agora as colunas (e nos lugares certos). Eu particulamente não gosto deste formato pois ele dificulta um pouco a leitura do texto no micro. Mas para impressão é um bom
formato.
> Manter fonte e tamanho da fonte: Esta opção mantém o formato do texto, eliminando o formato da página, permitindo você configurar a página do jeito desejado. Este é o formato que prefiro.
> Remover todas as formatações: O texto é salvo desconsiderando tanto as formatações de
página quanto de texto. O resultado é um arquivo onde todas as letras tem um mesmo tamanho e
usado uma única fonte. É formato dos arquivos txt.
Como um último item existe, em geral já marcado, “Manter figuras”. Caso as figuras não interessem é só desmarcar este item.
7-Sobre Figuras
Como eu escrevi em “algum lugar do passado” deste texto, o programa automaticamente identifica
as figuras, que são escaneadas como imagens e estas são adicionadas ao texto mais ou menos na
posição em que se encontram no original, mas porém, há dois pequenos inconvenientes:
1: Quando o imagem possuir texto, o programa pode reconhecer esse texto e tirá-lo da figura;
2: Não é possível fazer uma boa edição dessa imagens. O Word permite o ajuste apenas de brilho
e contrastes, não podendo mudar resolução, editar cores, gama, etc.
Recomendação: Se houver muitas imagens é mais prático deixar o FineReader cuidar delas. Se você quiser uma maior qualidade, e para as imagens coloridas, escaneie separadamente. Foi o que eu fiz no livro “O veleiro de cristal”, de José Mauro de Vasconcelos(que já está navegando pela rede!), que contem imagens preto e branco e coloridas, as quais foram escaneadas separadamente uma a uma.
8-Pré-revisão
É importante fazer uma pré-revisão do livro escaneado. Isto porque quem escaneia tem o livro em mãos (coisa que os outro leitores não vão ter), o que facilita a correção dos erros. O jeito mais prático de fazer esta correção é usar o Word, pois ele marcará em vermelho os possíveis erros ortográficos e em verde os possíveis erros de gramática (a minha experiência indica que mais de 90% dos erros marcados em verde não são erros). É também um processo tedioso (para um livro de 200 páginas
leva-se cerca de 2 horas, ou melhor, eu levo, talvez gente mais capacitada possa ir mais rápido) Nesta fase corrigem-se algumas falhas do programa tais como:
- palavras separadas por hífens: Nos livros, quando uma palavra não cabe na linha, esta é separada silabicamente por um hífem (ah! isso me lembra dos meus velhos tempos de escola! Ainda bem que eles já passaram!!!). Na grande maioria dos casos o FineReader os elimina, porém, principalmente na última linha de uma página o programa não o faz corretamente, provavelmente
porque a palavra está dividida em duas páginas (o inicio da palavra no final de uma página e o final da palavra no início da página seguinte)
- quebra de parágrafo: algumas vezes os parágrafos aparecem
quebrados (como no exemplo deste item, onde a palavra “quebrados” deveria seguir a palavra “aparecem”. Isto ocorre porque as vezes(muito raramente) o FineReader confunde o final de uma linha com o final do parágrafo. Isto pode ser evidenciado marcando todo o texto e escolher a opção “Justificar” do Word, o que também dará uma melhor aparência ao texto.
- palavras reconhecidas erroneamente: alguns textos não apresentam uma uniformidade na cor das letras, umas letras podem estar mais claras que outras. Isto induz a o programa OCR a cometer erros como trocar vote por voce, mim por niim, ja por ia, por exemplo. Este erros aparecem facilmente sublinhados em vermelho no Word.
-número exagerado de espaços: É comum no texto reconhecido aparecem mais espaços que o necessário entre as palavras. Mais isto é simples de se resolver, basta usar o comando “substituir” do Word para substituir dois espaços por um, repetindo o procedimento até o Word informar o valor de 0 (zero) substituições efetuadas.
O meu procedimento normal quando escaneio é:
1) Escanear o livro em partes e salvar, só mantendo fonte e tamanho da fonte e no formato doc;
2) Em um modelo vazio, formatado em 13 por 20 cm, 1 cm para todas as margens, importo as partes do livro;
3) Seleciono todo o texto, escolho o item Formatar do menu do Word, a seguir o item Parágrafo, usando o alinhamento “justificado” e em “recuo”, especial > primeira linha;
4) Elimino os espaços extras utilizando o “substituir” do Word;
5) Passo uma vista d’olhos por todo texto, atentando para as marcações em vermelho e em verde (as cores de Portugal) do Word;
9-Revisão
Ainda assim erros poderão existir no texto escaneado. Por exemplo, pode ter havido a troca de “se” por “de” e o Word não nos alertar. Pode ser que acidentalmente viremos mais de uma pagina na hora de escanear (já aconteceu comigo, mas consegui perceber durante a pré-revisão), Podem faltar palavras e até linhas. Para descobrir isso só lendo todo o texto escaneado e corrigindo (e mesmo assim muitos erros passam. Pra se ter uma idéia em alguns livros o Word apontou-me erros que (eu fui verificar) existiam nos próprios originais. Os livros passam pelo autor, editor, revisor e sei lá mais quem e ainda sim são impressos com erros (há muito tempo atrás eu li um texto de Monteiro Lobato onde ele comentava justamente esses erros).
Erro de links e duvidas entre em contato e me ajude curtindo a pagina do facebook
Contato: maguarihost@gmail.com
FACEBOOK
https://www.facebook.com/blogdobifecomfarofa/
AJUDE O SITE A FICAR NO AR
https://www.facebook.com/blogdobifecomfarofa/
AJUDE O SITE A FICAR NO AR
Mantenha o Site no ar, ajudando com qualquer valor.... clique na imagem abaixo:





Nenhum comentário:
Postar um comentário